
REST API to perform complex long run job – Example with MuleSoft
In recent days most of customers want to implement their solutions using API to work independently within different systems. API Led Architecture is one of the important system solution architecture adopted in the latest software implementations. We are talking about the REST APIs and the context is to process complex or data intensive operations (e.g., big data processing, back-up/batch jobs) might require a long time. As examples we can consider the following scenarios:
- Customer wants an API which will take care Complete Order to Delivery Process. The API should revert back all transactions in case of both functional and system failure.
- Customer wants an API which will upload the data in Oracle using FBDL process which normally takes long time to execute due to large volume of data and complex validation.
- Customer wants an API which will check Employee background using various third party background check software.
In this blog we review the technical problem, the solution, and any related consequences.
Technical Problem:
Our operation require a long time to process, how can a client retrieve the result of such an operation without keeping the HTTP connection open for a too long time? There may be a timeout for HTTP connections because every open connection allocates a certain amount of memory at the server and the client. The problem is to optimize resources for open connections and for computations whose result will not be received by the client in case of a timeout.
Also due to unreliability of network connections, the client may lose the connection before the server has completed processing the result. The longer the server takes to respond to the client, the higher the chances are that the client may no longer be available to receive the result. The expensive computations process in server side and are repeated every time if client resends the request in case the connection on the previous one is dropped. Performing expensive computations and delivering their results are two main concerns that make completely different demands on the server infrastructure.
Solution:
There could be two solutions for the above stated problem described below:
- Client polling approach: We can define the long run operation itself as an API resource with a response which will tell client where to find the results to get the different state of operations. The long run operation “state” is exposed as a resource which the client can get as a “HATEOAS” from the previous call. The client may poll this operation states as status and notify other process for subsequent action. Since the output has its own URI, it becomes possible to GET it multiple times, as long as the state has not been deleted. Moreover, the long running operation can be cancelled with a DELETE request. A visualization of the solution is provided in the following diagram:
-
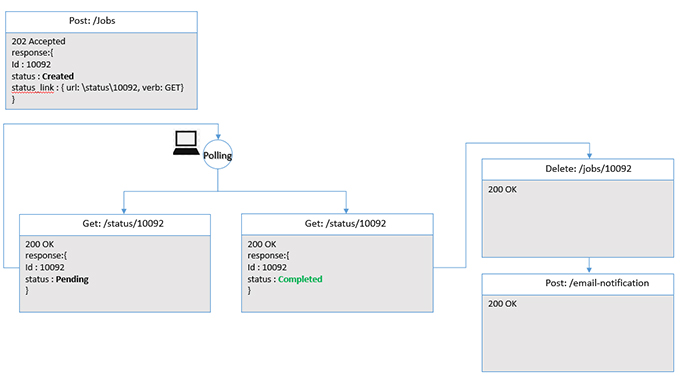
Fig. 1: Long Run API with Polling
- Client Callback through web hook URL approach: Here we can expose API resource as long run job and client will send a pre-existing client side callback URL (web hook URL) while requesting the resource and server operations state will be notified through this callback URL. In this case client does not have to poll for the status, it will be notified automatically from server side through the callback URL as and when there is any change in server operation status. In this case also, the long running operation can be cancelled with a DELETE request at any time if needed. A visualization of the solution is provided in the following diagram:
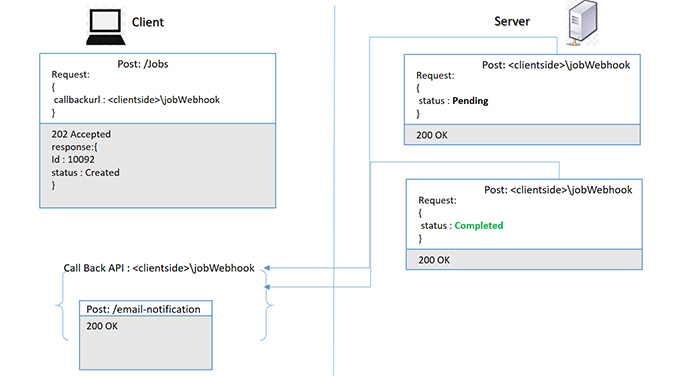
Fig. 2: Long Run API with Client Callback (Web hook) URL
Solution in Mulesoft:
We can achieve the solution using Mule VM connector by routing the message dynamically through the VM connector. In server side after getting the client request application it can start an asynchronous process by publishing an event through the VM connector. The application can assign a GUID as JobId to the publish message to track the different Job requested by the client. The same JobID can be sent to the client as response so that client application can track the status for a particular job. The server side API implementation in Mule will look like as below:
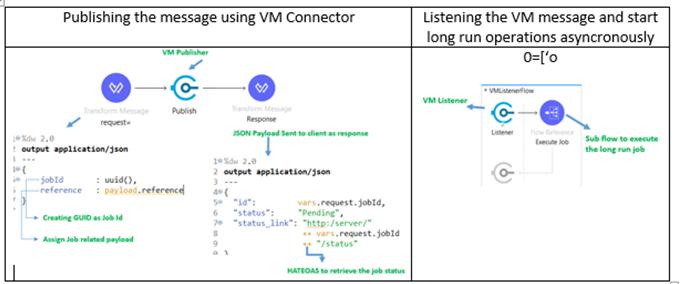
Fig. 3: Long Run API Job Publisher and Listener
To store the status during the execution of long run job, Mule “Object Data Storage” key value functionality can be used. Application can store different stage values of the operations (status) as value where key is the JobId. In case of a concurrent API call, the application will generate different GUID and a different instance of VM Listener will be created. There will be no overlapping of status value since we are storing the status value against the different GUID as key.
The client application can poll the job status based on the URL link (HATEOAS) retrieved as API response.
To notify the callback URL (web hook) with a different status, we can use the REST connector as described below during the “ExecuteJob” sub flow execution. Following is an example of notify different status during “order – delivery” job execution.
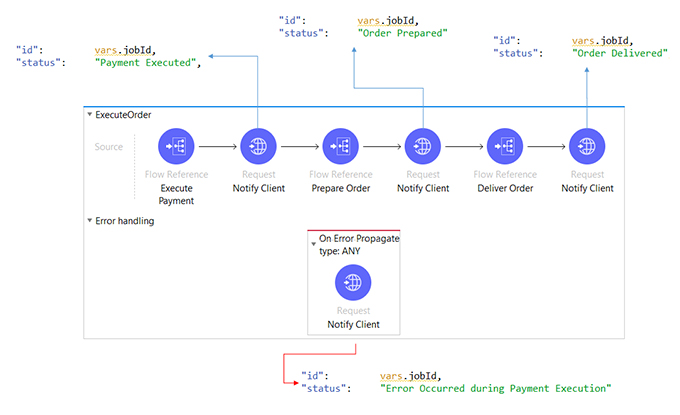
Fig. 4: Long Run API Job & notifying different status in mule flow
Consequences:
Benefits:
- Scalability: The client doesn’t have to keep the connection open with the server for the entire duration of the request. This has a positive impact on the number of clients that the server can handle concurrently.
- Shared results: The link to the result can be shared among multiple clients that can retrieve it without needing the server to re-trigger it again for each client.
- Resource optimization: Due to immediate response from server, client does not have to block any resource for a long span of time.
Liabilities:
- Polling: The client needs to implement polling, which if done too frequently, may put an additional burden on the server and consume unnecessary bandwidth. To mitigate this server can provide progress information in percentage and Client can optimize GET call using this progress information. We can use this method where Client has security restriction to expose API Gateway to the other third party vendor or if we like to optimize shared memory.
- Web hook: Client has to create API Gateway to expose the URL to server. Server-Client security protocol need to be established properly. Here client has to store all relevant information that were sent through the initial request to make the final report with in this call back handler. This approach can be used where we need to have multiple statuses of a job from different vendors, like doing background check of an employee during employee hiring where we need to know multiple statuses from different vendor to report the current status.
- Server storage consumption: Depending on the type and size of the result, storage space will be consumed if clients forget to delete the job results and these are not deleted automatically after a certain period of time.
Conclusion:
Above design architecture can resolves all the technical problems those we have discussed earlier. Moreover there are two ways to address this use case scenario. We can apply any one of the solution either the polling or the callback approach based on customer environment and requirement. The main methodology of this architecture is design your API to run the process asynchronously and the API design using this architecture is smart enough to notify clients about the long run process status at any point of time. The architecture is also cable to optimize resources and expensive server side computation process.