
Parallel Processing Implementation using MuleSoft
In current world, we do build lot of integrations using different Middleware tools. Sometimes it can be very useful to be able to process integration flows in parallel and aggregate the result. This way we can drastically improve the performance of a service. In this blog, we will share a use case which explains how we can do using MuleSoft.
Let’s assume, we want to process a list of user records and send the result back to the client request. This can be achieved in one of the following ways.
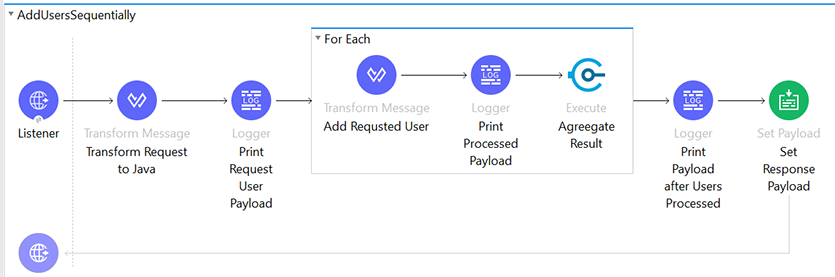
1. Using Sequential (For Each) Block:
Build an API using “For Each” scope to process the list of records, aggregate the results and send the consolidated response back to the client request.
Below is an example that processes the list of user records sequentially.
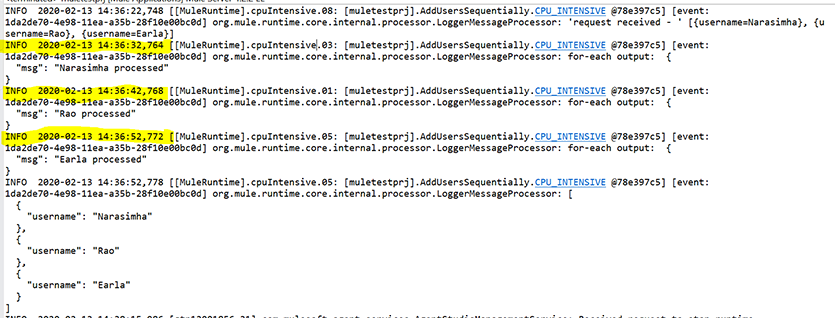
Problem: The problem with this approach was, it consumed a lot of time in processing the list of the records. See the log below, for each record it took around 10 seconds to process.
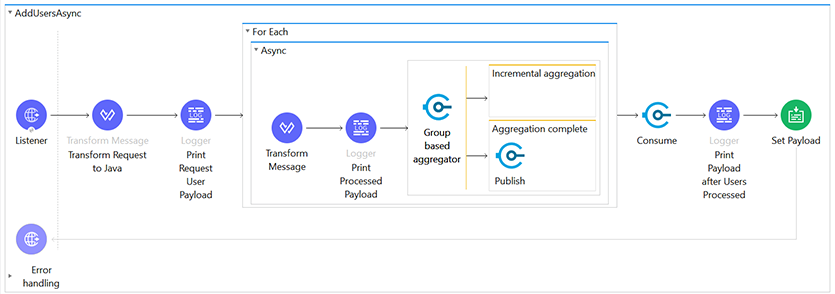
2. Using Async Block:
To improve the performance of the previous client request, let’s introduce “Async Block” inside the sequential processing (for each scope) and add a group based on aggregators to consolidate the result. The total flow will look something like the example below:
See the log below, in this example the list of the records were processed in parallel and the response time has been reduced to less than 1 sec to process all the records.
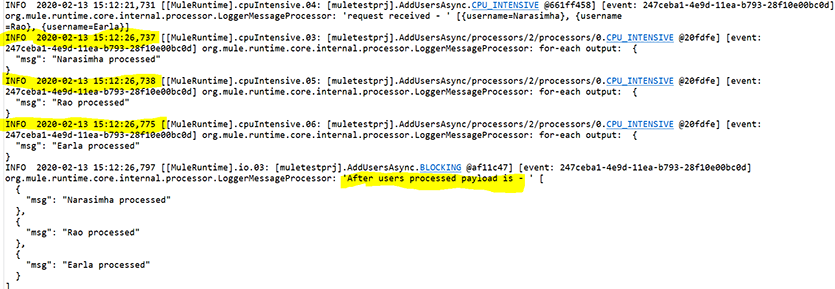
Problem: Even with this approach we could also see cross communication issues between the threads where multiple threads were processing in parallel. The issue occurs when the message is published to the VM component through thread1 and is consumed by the VM consume component of thread2, thus causing an unexpected behavior.
3. Using ‘Parallel For Each’:
To build faster and more efficient integrations, Mulesoft has provided a hidden feature named “Parallel For Each” which helps to resolve all of the above issues.
The Parallel For Each scope enables you to process a collection of messages by splitting the collection into parts that are simultaneously processed in separate routes within the scope. After all messages are processed, the results are aggregated following the same order they were in before the split, and then the flow continues.
This feature is not available in the Anypoint Studio Mulesoft Palette view, you must manually configure Parallel For Each scope in the XML. The total flow will now look like the below example:
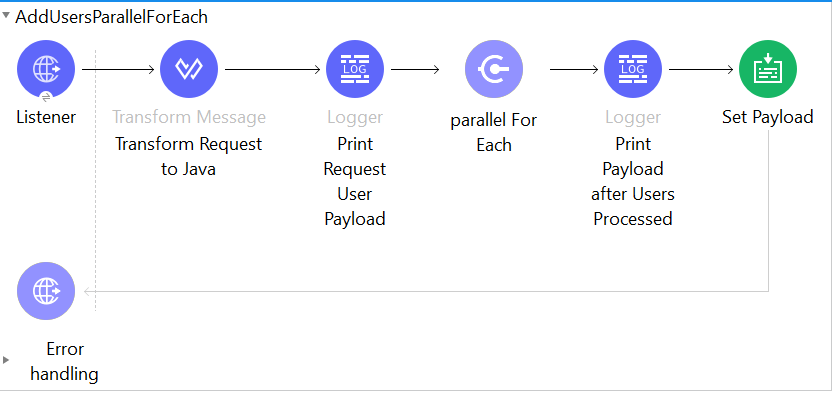
With this approach, we can process the list of the records in parallel and also reduce the response time to less than 1 sec. We did not see any cross communication issue between the threads.
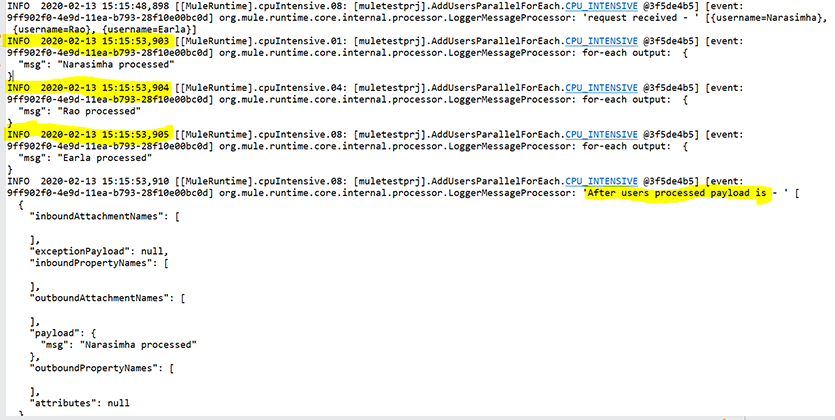
Conclusion: To summarize, by implementing the ‘Parallel For Each’ approach we could build a faster and very efficient integration.
If you have any questions, please leave your comments or suggestions below. For more blogs, check out https://appsassociates.com/